Selected academic projects
Estimating the success of re-identifications in incomplete datasets
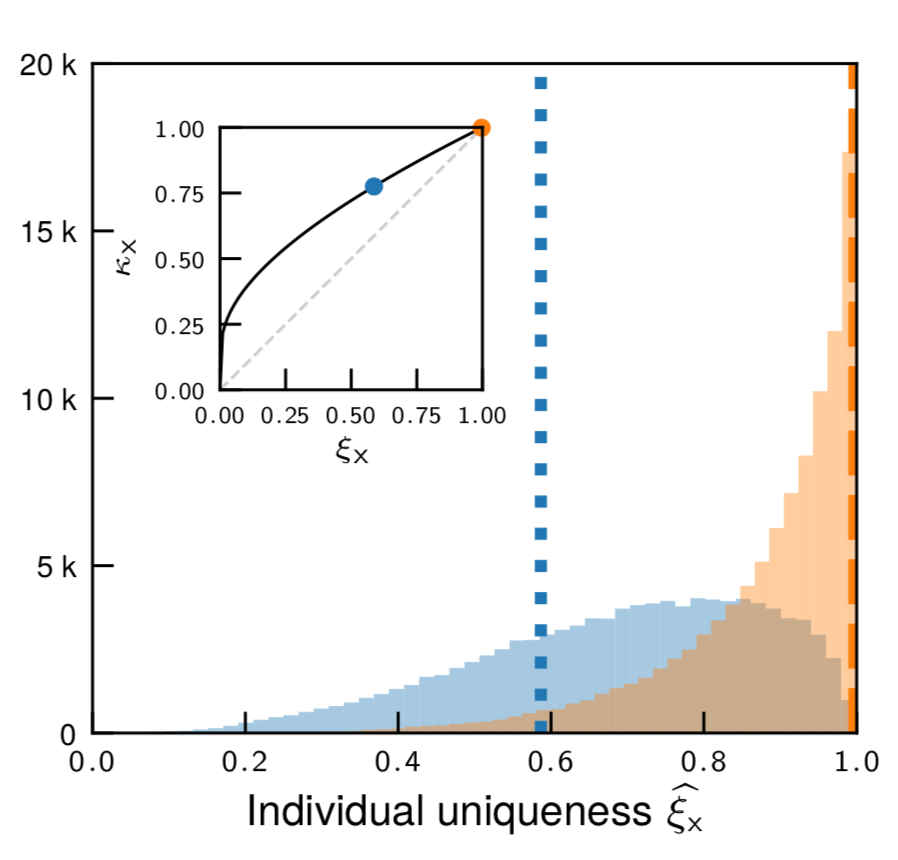
Anonymizing datasets through de-identification and sampling them has been a central tool to address privacy concerns when sharing data. Despite re-identifications regularly happening, how can one be sure they truly identified the right person? We proposed a generative copula-based method that can accurately estimate the likelihood of a specific person to be correctly re-identified, even in a heavily incomplete dataset. Using our model, we find that 99.98% of Americans would be correctly re-identified in any dataset using 15 demographic attributes. Our results suggest that even heavily sampled anonymized datasets are unlikely to satisfy the modern standards for anonymization set forth by GDPR and seriously challenge the technical and legal adequacy of the de-identification release-and-forget model.
[How to cite] Rocher, L., Hendrickx, J. M., & de Montjoye, Y. A. (2019). Estimating the success of re-identifications in incomplete datasets using generative models). Nature communications, 10 (1), 3069.
[Selected press] New York Times, Guardian, CNBC, The Telegraph, TechCrunch, Technology Review, New Scientist, Gizmodo, Scientific American, RT, Forbes, El Pais (ES), Sueddeutsche Zeitung (DE), Le Soir (FR), La Libre (FR), L’Echo (FR), De Morgen (NL)
When the signal is in the noise: Exploiting Diffix’s Sticky Noise
Based on the idea of ‘sticky noise’, Diffix has been recently proposed as a novel query-based mechanism satisfying alone the EU Article 29 Working Party’s definition of anonymization. According to its authors, Diffix adds less noise to answers than solutions based on differential privacy while allowing for an unlimited number of queries. We propose a new class of noise-exploitation attacks, exploiting the noise added by the system to infer private information about individuals in the dataset. We show how to implement and optimize the developed attack, targeting 55.4% of the users and achieving 91.7% accuracy, using a maximum of only 32 queries per user. Our attacks demonstrate that adding data-dependent noise, as done by Diffix, is not sufficient to prevent inference of private attributes.
[How to cite] Gadotti A., Houssiau F., Rocher L., Livshits B., de Montjoye Y. A., When the signal is in the noise: Exploiting Diffix’s Sticky Noise. 28th USENIX Security Symposium (USENIX Security 19). (2019).
[Selected press] TechCrunch, Wall Street Journal.
Complete publication list on Google Scholar.
Selected personal projects
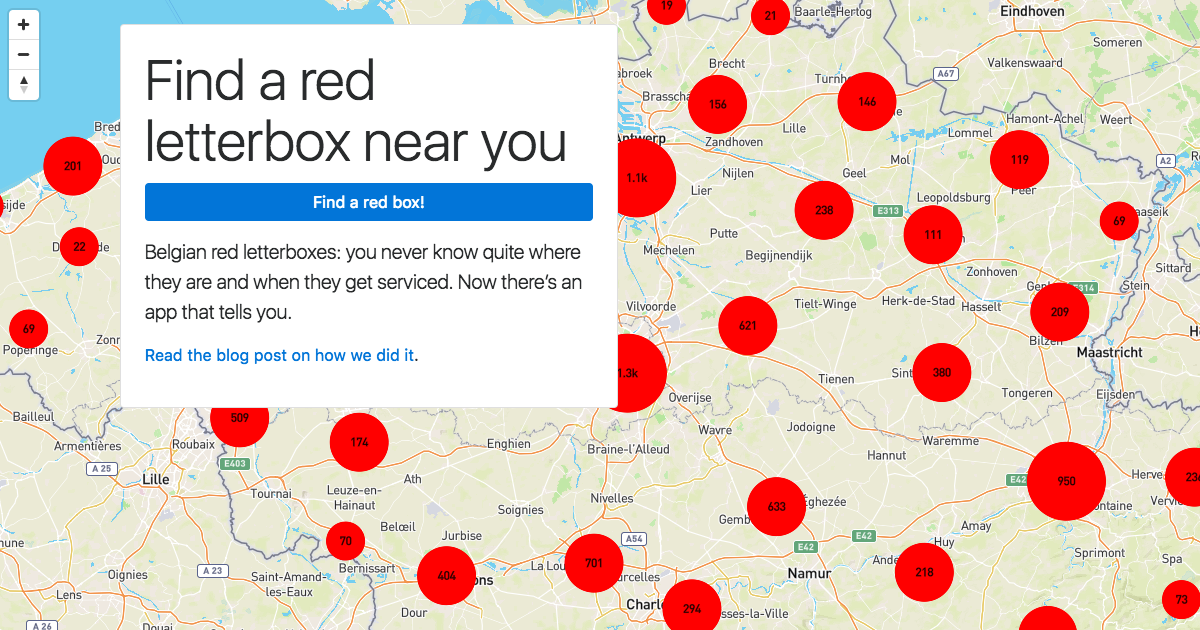
Find a red letterbox near you
In Belgium, we send letters. Every year though, the market for postal letters decreases by about 5%. Post offices close. Mail boxes disappear. So when we need to send a letter, we might not know exactly where to post it. Using our application, everyone traveling across Belgium can now easily find not only the closest mail box, but also quickly which ones will still be fetched before the end of the day. Our application harvest exact location and service time from BPost unreleased data, crucially calling for more open data in Belgium.
[Selected press] VivreIci (FR), L’Avenir (FR).
written on January 1, 0001